راهنمای جامع فایل robots.txt

حتما تا امروز از اینجا و آنجا دست کم یک بار نام فایل robots.txt به گوشتان خورده. اگر نام این فایل را شنیده اید ولی دقیقا نمیدانید که این فایل چیست و چه کاربرد هایی دارد و یا اگر به طور کلی با ماهیت این فایل آشنا هستید و میخواهید یک قدم فراتر گذاشته و به کلیه ی جوانب استفاده از آن مسلط شوید، این مقاله مخصوص شماست. از شما دعوت میکنیم که در ادامه ی این مطلب با مسترکد همراه شوید.
فایل robots.txt چیست و چه کاربردی دارد؟
robots.txt همانطور که از نامش هم مشخص است، یک فایل متنی مخصوص ربات موتور های جستجو است که از ساختار تعریف شده ی خاصی استفاده میکند. به این فایل گاهی با عنوان پروتکل عدم شمول ربات ها یا Robots Exclusion Protocol هم اشاره میشود. اما در واقع محتوای این فایل دارای استاندارد رسمی که از طرف سازمانی رسمی تعیین شده باشد نیست و تنها از سینتکسی پیروی میکند که از دیرباز بین نسخه های قدیمی موتور های جستجو مورد توافق بوده است.
موتور های جستجو با خزیدن در میان صفحات سایت شما، آن را ایندکس میکنند و با دنبال کردن لینک ها از سایتی به سایت دیگر میروند. هرگاه یک خزنده ی موتور جستجو وارد دامنه ای که قبلا با آن مواجه نشده میشود، ابتدا فایل robots.txt آن سایت را فراخوانی میکند تا بداند که مجاز است به کدام بخش های سایت سرک کشیده و محتوای موجود را ایندکس کند. فایل robots.txt معمولا توسط موتور های جستجو کش میشود ولی به هر حال در صورتی که در محتوای این فایل تغییری ایجاد کنید، با توجه به ریفرش شدن این فایل توسط موتور های جستجو در طول روز، دستورات جدید شما توسط موتور های جستجو دنبال خواهند شد.
توجه داشته باشید که قرار دادن دستورات نامناسب در این فایل، و منع کردن ربات ها از دسترسی به قسمت های ضروری سایت، میتواند ضربه ی شدیدی به سئوی سایت شما وارد کند. بنابراین در زمان ویرایش این فایل و افزودن دستورات جدید، حتما نهایت توجه را به کار بگیرید و بدون اینکه از کار خود مطمئن باشید، دست به اعمال تغییر در این فایل نزنید.
شاید برایتان جالب باشد که بدانید در مقابل فایل robots.txt فایلی با نام humans.txt هم وجود دارد. با کلیک بر روی اینجا میتوانید اطلاعات بیشتری در رابطه با این فایل کسب کنید.
فایل robots.txt را در چه محلی باید قرار داد؟
فایل robots.txt باید همیشه در روت سایت شما قرار بگیرد به نحوی که فرضا اگر آدرس سایت شما http://domain.com باشد، بتوان این فایل را از آدرس http://domain.com/robots.txt مورد دسترسی قرار داد. توجه داشته باشید که حتی وقتی که یک خزنده ی موتور جستجو میخواهد یک زیر فولدر از یک دامنه را نگاه کند، باز هم فایل robots.txt را از ریشه ی سایت فراخوانی خواهد کرد. مثلا وقتی موتور جستجو در حال مشاهده ی http://domain.com/example باشد، فایل robots.txt با آدرس http://domain.com/robots.txt فراخوانی خواهد شد.
نکته ی حائز اهمیت این است که اگر سایت شما هم بدون www و هم با www و یا هم با http و هم با https قابل دسترسی باشد، باید توجه کنید که در تمامی این حالت فایل robots.txt شما باید میان تمامی این آدرس ها کاملا یکسان باشد، در غیر این صورت ربات های موتور جستجو در خزیدن سایت شما سردرگم خواهند شد.
مزایای استفاده از فایل robots.txt
یک نکته ی جالب وجود دارد که شاید تا امروز اطلاعی از آن نداشتید، (شاید هم داشتید!) گوگل (یا به طور کلی موتور های جستجو) مقدار زمان مشخصی را صرف خزیدن در یک وبسایت میکنند و در هر بار بازدید تعداد صفحات محدودی را میخزند. این مقدار زمان و صفحه برای هر وبسایت کاملا متفاوت بوده و بر اساس فاکتور های خاصی مثل پیج رنک و … آن سایت تعیین میشود. به این مقدار Crawl Budget میگوییم. خوب، با کمی محاسبه ی دو دو تا چهارتایی متوجه میشوید که وقتی در سایت شما بی نهایت محل برای خزیده شدن وجود داشته باشد، بسیاری از محتوای ارزشمند شما ممکن است شانس دیده شده توسط موتور جستجو را از دست بدهند. پس چاره چیست؟ وقتی شما محل هایی که نباید توجه موتور های جستجو مورد دسترسی قرار بگیرند را از لیست بخش های قابل ایندکس شدن سایتتان حذف میکنید، به بخش های ارزشمند سایتتان شانس خزیده شدن و مورد توجه قرار گرفتن را میدهید.
سایت هایی که در آدرس آنها تعداد زیادی متغیز با مقادیر ممکن بالا وجود دارد، باید حتما به این نکته توجه کنند که ترکیب این متغیر ها و مقادیر ممکن آنها ممکن است به ایجاد 100 ها یا گاها هزاران آدرس مختلف قابل ایندکس کردن بیانجامد. حتما سریعا میتوانید حدس بزنید که چنین اتفاقی میتواند سریعا Crawl Budget سایت شما را به اتمام برساند. برای جلوگیری از این اتفاق، کافی است ربات های موتور جستجو را از خزیدن این آدرس ها که دارای پارامتر هستند منع کنید، تا آنها تنها به آدرس اصلی که مد نظر شماست توجه کنند. با قرار دادن کد زیر در فایل robots.txt میتوانید کلیه ی ربات ها را از دنبال کردن آدرس های دارای پارامتر در سایت خود منع کنید :
1 | Disallow: /*?* |
معایب استفاده از فایل robots.txt
یکی از معایب فایل robots.txt این است که گرچه توسط این فایل میتوانید به ربات موتور جستجو بگویید که به محلی در سایت شما مراجعه نکند ولی نمیتوانید به آن بگویید که آدرس بخش مورد نظر را در لیست نتایج جستجو نمایان نکند. یعنی فرضا ممکن است شما آدرس یک پوشه را توسط robots.txt بلاک کرده باشید، ولی آدرس این پوشه ممکن است در زمان جستجو، در میان نتایج جستجو به چشم بخورد. در چنین حالتی اگر قصد شما این است که واقعا آدرس مورد نظر در نتایج جستجو هم پدیدار نشود باید بجای استفاده از فایل robots.txt از متا تگ noindex استفاده کنید. نکته ی مهم این است که برای دیده شدن متا تگ noindex توسط موتور های جستجو، خزنده ی موتور جستجو باید قادر به دیدن صفحه ی مورد نظر باشد. پس دسترسی به صفحه ای که دارای متا تگ noindex است را نباید از طریق فایل robots.txt برای ربات مورد نظر غیر مجاز کنید. در غیر این صورت تگ noindex کاملا بی کاربرد و بی فایده خواهد بود.
نقطه ی ضعف دیگر استفاده از فایل robots.txt برای جلوگیری از دسترسی ربات ها به بخش خاصی از سایت این است که وقتی خزنده ی موتور جستجو مجاز به مشاهده ی صفحه ای از سایت نباشد، بنابراین نمیتواند لینک های موجود در آن صفحه را نیز دنبال کرده و به آنها ارزش اختصاص دهد. اگر موتور جستجو مجاز بود که صفحه را مشاهده کرده و لینک ها را دنبال کند ولی صفحه را ایندکس نکند، آنوقت همه چیز حل میشد. ( در چنین مواقعی میتوانیم از تگ noindex follow استفاده کنیم)
ساختار و سینتکس فایل robots.txt
فایل robots.txt از یک یا چند بلاک حاوی دستورات مشخص تشکیل میشود. هر بلاک با خطی که مشخص کننده ی User-agent یا همان نام ربات جستجوگر مورد نظر است شروع میشود. با استفاده از مقدار user-agent میتوانید ربات خاصی را هدف گرفته یا به طور کلی، دستوری را خطاب به همه ی آنها در این فایل درج کنید. به عنوان مثال بلاک ها و دستوراتی که از آنها حرف زدیم میتوانند شکل ساده ی زیر را داشته باشند :
1 2 3 4 5 6 7 8 | User-agent: * Disallow: / User-agent: Googlebot Disallow: User-agent: bingbot Disallow: /not-for-bing/ |
توجه داشته باشید که در دستورات بالا تفاوتی ندارد که عبارت Allow یا Disallow را با حروف کوچک مینویسید یا بزرگ. اما در نام دایرکتوری ها باید حتما حروف بزرگ و کوچک را رعایت کنید چرا که مثلا از دید ربات های جستجوگر، آدرس /photo/ با /Photo/ متفاوت خواهد بود.
در ادامه به شرح دستورات استفاده شده در کد بالا خواهیم پرداخت.
User-agent : اولین دستور در هر بلاک از دستورات فایل robots.txt همین User-agent است. این دستور مشخص میکند که آنچه در بلاک مربوطه درج شده، مربوط به کدام یک از ربات های موتور جستجوست. در مورد خطاب قرار دادن خزنده های موتور جستجو باید این نکته را مد نظر داشته باشید که هر موتور جستجو بجز خزنده ی اصلی اش که عمومیت بیشتری دارد، ممکن است خزنده های متعددی داشته باشه. مثلا خزنده ی مخصوص تصاویر، خزنده ی مخصوص اخبار، خزنده ی موبایل و … بنابراین بر اساس نیاز خود میتوانید نام هر یک از آنها را که مد نظر شماست مورد خطاب قرار دهید. مثلا در زیر user-agent خزنده ی عمومی گوگل را برایتان درج کرده ایم :
1 2 | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
حال وقتی میخواهیم این خزنده را در فایل robots.txt مورد خطاب قرار دهیم، تنها درج عبارت User-agent: Googlebot کفایت خواهد کرد.
در صورتی که در فایل robots.txt دستوراتی را درج کرده باشید که چند بلاک مختلف آنها برای یک خزنده صادق باشد، خزنده ی موتور جستجو همیشه دستوری را که به طور واضح تر به آن خزنده ی خاص اشاره میکند انتخاب کرده و دستورات همان بخش را اجرا خواهد کرد. مثلا فرض کنید در فایل robots.txt خود یک بلاک مخصوص *، یک بلاک مخصوص Googlebot و یک بلاک مخصوص Googlebot-news درج کرده باشید. در این حالت اگر خزنده ی Googlebot-Video وارد سایت شما شود، در میان این دستورات از دستورات مخصوص Googlebot پیروی خواهد کرد و اگر خزنده ی Googlebot-news وارد سایتتان شود، از دستورات درج شده در بلاک مربوط به Googlebot-news تبعیت خواهد نمود.
در تصویر زیر تعدادی از عمومی ترین و شناخته شده ترین user-agent های موتور های جستجو را که میتوانید در فایل robots.txt مورد استفاده قرار دهید، برای شما درج کرده ایم :
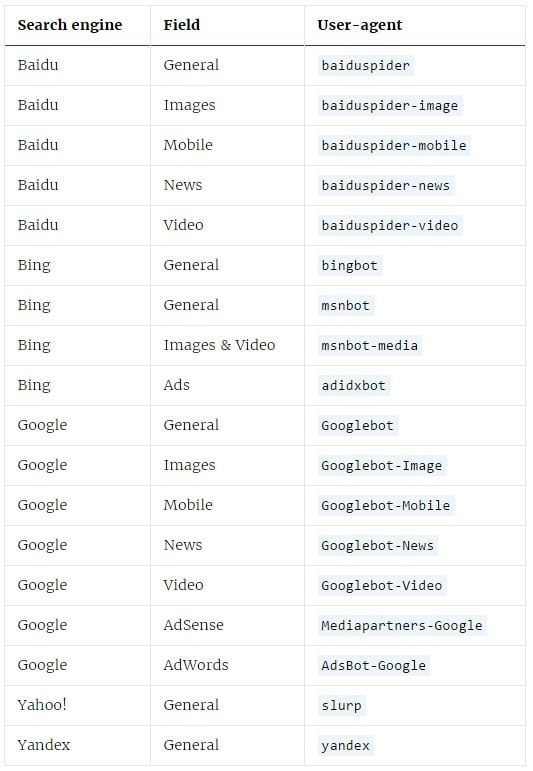
Disallow : آنچه در جلوی این عبارت درج میشود نشان میدهد که ربات مورد نظر شما مجاز نیست به بخشی که در این قسمت درج شده دسترسی پیدا کند. شما میتوانید چندین خط از این دستور در ادامه ی هم در فایل robots.txt خود داشته باشید و در هر خط دسترسی به بخش خاصی را منع کنید. خالی بودن جلوی این عبارت نشان میدهد که دسترسی به تمامی بخش های شما مجاز است. به مثال های زیر توجه کنید :
1 2 | User-agent: * Disallow: / |
کد بالا میگوید که هیچ یک از موتور های جستجو مجاز به خزیدن در هیچ یک از بخش های سایت شما نیستند. (البته همیشه مد نظر داشته باشید که user-agent ها مجبور نیستند به این فایل اهمیت بدهند و این فایل تنها توسط موتور های جستجویی که به این قوانین احترام بگذارند، مورد توجه قرار میگیرد)
1 2 | User-agent: * Disallow: |
کد بالا میگوید که دسترسی به کلیه ی بخش های سایت شما برای تمامی موتور های جستجو مجاز است.
1 2 | User-agent: googlebot Disallow: /Photo |
و اما کد بالا اینطور میگوید که گوگل بات مجاز نیست وارد پوشه ی Photo در سایت شما شود. (مجاز نیست محتوای آن را crawl کرده یا در آن بخزد!) توجه داشته باشید که این امر شامل تمامی زیر پوشه های فولدر Photo نیز میشود.
استفاده از وایلدکارد و عبارات منظم (Regular Expression) در robots.txt
گرچه عبارت منظم و وایلدکارد ها به صورت رسمی در فایل robots.txt پشتیبانی نمیشوند ولی اکثر موتور های جستوی بزرگ، این عبارات را در این فایل به خوبی خوانده و اجرا میکنند. بنابراین با استفاده از این عبارات شما به سادگی میتوانید گروهی از فایل های خاص را بلاک کنید. به کد زیر توجه کنید :
1 2 | Disallow: /*.php Disallow: /copyrighted-images/*.jpg |
با استفاده از دستور بالا اعلام کرده ایم که crawl کردن فایل های دارای پسوند php و کلیه ی تصاویر دارای فرمت jpg که در فولدر copyrighted-images قرار گرفته باشند، غیر مجاز است.
Allow : دستور Allow جزو دستورات غیر رسمی / غیر استاندارد فایل robots.txt است اما به هر حال توسط اکثر موتور های جستجو قابل شناسایی است. کارکرد این دستور از عنوان آن مشخص است. این دستور به خزنده ی مربوطه میگوید که میتواند در محل خاصی از سایت بخزد. مثلا فرض کنید که میخواهیم دسترسی به فولدر wp-admin را ممنوع کنیم ولی دسترسی به فایل admin-ajax.php که درون این فولدر قرار گرفته، کماکان برای خزنده های موتور های جستجو مجاز باشد. در این شرایط از دستور زیر استفاده میکنیم :
1 2 | Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php |
برخی از دستورات کمتر شناخته شده که در این فایل قابل استفاده هستند عبارتند از noindex, host, crawl-delay و sitemap. از آنجایی که این دستورات توسط همه ی موتور های جستجو قابل شناسایی نیستند و همچنین برای آنها جایگزین های بسیار مفید تر و کاربردی تری نیز وجود دارد، بنابراین در این مقاله به شرح این دستورات نخواهیم پرداخت. (تمامی این موارد از طریق کنترل پنل های ارائه شده توسط موتور های جستجو (مانند گوگل وبمسترز) و یا در سطح خود سایت قابل اجرا هستند و نیازی به اعمال آنها از طریق فایل robots.txt نیست.)
تست و اعتبارسنجی فایل robots.txt
بعد از اعمال تنظیمات دلخواه، این مسئله بسیار حائز اهمیت است که حتما فایل robots.txt سایت خود را تست کنید. وجود مشکل در این فایل میتواند به فراموشی ابدی سایت شما توسط موتور های جستجو منجر شود. بنابراین این مسئله را اصلا شوخی نگیرید. برای انجام این کار ابزارهای گوناگونی وجود دارد ولی مسترکد برای تست فایل robots.txt خود از گوگل وبمسترز کمک میگیرد. برای استفاده از ابزار تست robots.txt کافی است وارد پنل خود در گوگل وبمسترز شوید و سپس از منوی Crawl به زیر منوی robots.txt Tester مراجعه کنید. در این بخش میتوانید فایل مورد نظر را برای دسترسی انواع خزنده های گوگل تست کرده و اطمینان حاصل کنید که همه چیز مرتب است و سپس نفس راحتی بکشید …
امیدواریم که پاسخ سوال های خود را در این مقاله یافته باشید.
سلام
توی مقاله اشاره کردید به آدرسهای دارای پارامتر
میشه یک مثال ازش بزنید؟ ممنون میشم
سلام
مثلا :
https://mrcode.ir/?p=3693
در آدرس بالا پارامتر p رو با مقدار 3693 به سایت ارسال کردیم.
نکته ی حائز اهمیت این است که اگر سایت شما هم بدون www و هم با www و یا هم با http و هم با https قابل دسترسی باشد، باید توجه کنید که در تمامی این حالت فایل robots.txt شما باید میان تمامی این آدرس ها کاملا یکسان باشد، در غیر این صورت ربات های موتور جستجو در خزیدن سایت شما سردرگم خواهند شد.
چه کاری باید انجام بدیم تو این حالت ؟؟ سایت من این مشکل رو داره و در آدرس بدون www یه فایل robots.txt دیگه نمایش میده
لطفا راهنمایی بفرمائید
تشکر
باید ببینید این فایل کجاست و از کجا خونده میشه (و از همه مهم تر بررسی کنید که اصلا چرا دو فایل نشون داده میشه) و بعد محتوای هر دو فایل رو یکسان کنید.
سلام ایا میشه ما کد
User-agent: *
Disallow:
را قرار دهیم
بعد این کد را هم زیرش قرار دهیم
Disallow: /wp-admin/
یعنی بگویم به همه سایت میتونه بره ولی به این فلدر نه ؟
اگر این روش غلط است پس چی باید بدهم
سلام
فکر نمیکنم این حالت صحیح باشه. باید فقط جایی که ممنوعه رو مشخص کنید. اگر اینطوری بنویسید در واقع دو تا حالت ضد هم مشخص کردید. اول گفتید همه جا مجازه بعد گفتید ادمین مجاز نیست. باید فقط بگید فلان دایرکتوری مجاز نیست.
با عرض سلام
احتراما به استحضار می رساند که ما می خواهیم یک دامنه را روی یک دامنه دیگر پارک کنیم (بدون ریدایرکت).
ولی با توجه به اینکه 2 دامنه باعث کاهش سئو می شود
می خواهیم یک دامنه را از طریق robot.txt برای موتور جستجو غیر فعال کنیم.
آیا این امکان وجود دارد؟
سلام خیلی کاربردی بود ممنونم.
وبلاگ من بهم اجازه دسترسی و ویرایش فایل روبوتس رو نمیده!
تو گوگل سرچ کنسول حدود 20 تا ارور مربوط به Robots.txt دارم
تو فایل روبتس وبلاگم که نگاه کردم نوشته:
/Disallow: /process
چیکار بکنم؟